Kinds of Query Parallelism
Inter-Query
Multiple SQL queries runs in parallel.
Intra-Query
- Inter-Operator
- Pipeline
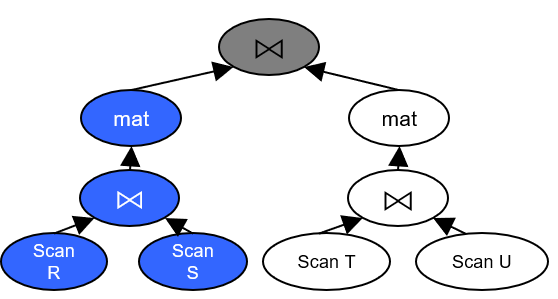
- Bushy (Tree): Sub-tree uses pipeline. Between sub-trees runs in parallel.
| Pipeline | Bushy (Tree) |
|---|---|
 |  |
- Intra-Operator
- Single query runs in parallel by partitioning.
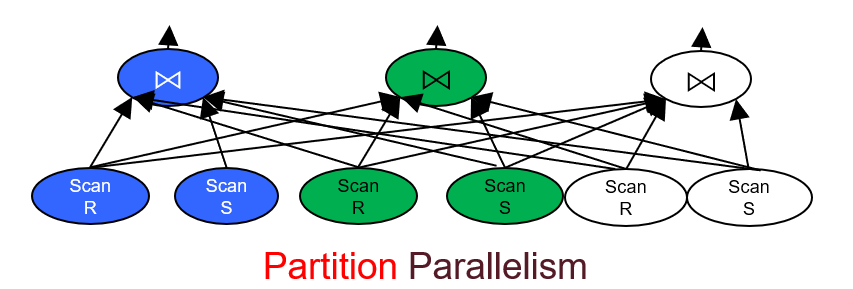
- Single query runs in parallel by partitioning.
Intra-Operator
Data Partition
Assume we have multiple machines, how can we partition data into these individual machines? Introduce several partitioning methods:
- Range: Good for equijoins, range queries and group-by
- Hash: Good for equijoins, group-by
- Round-Robin: Good for spreading load
Parallel Scans
We can do parallel scans on multiple machines:
- Simply scan in parallel and merge result as the ouput.
- : If we use range or hash partitioning, we can skip entire sites that have no tuples satisfying .
- We can build indexes at each partition
Lookup by key
- If data partitioned on function of key (range and hash for example), we can only lookup the relevant node.
- Otherwise we have to broadcast lookup to all nodes.
Insert a key
- Similarly, if data partitioned on function of key, we route the insert to relevant node.
- Else, route insert to any node is ok.
Insert a unique key
- Data partitioned, route the insert to the relevant node;
- Else, broadcast lookup and collect results. If not exists, insert anywhere.
Hash Join
Naive Parallel Hash Join
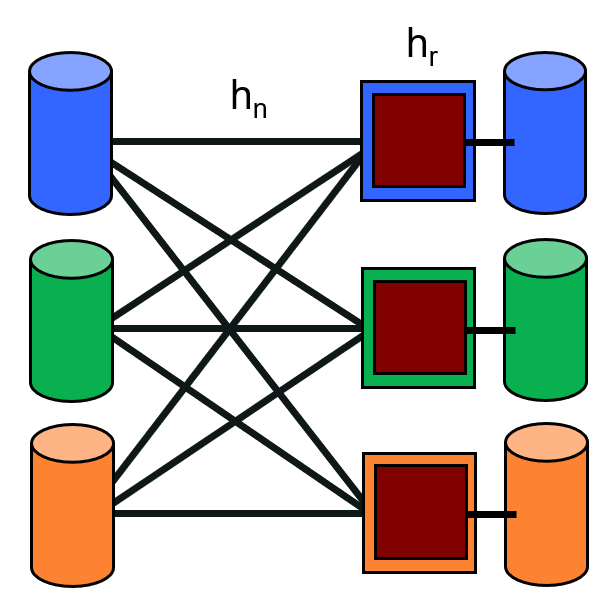
- Phase 1: shuffle each table across machines (using ).
- Phase 2: receivers proceed with naive hashing in a pipeline as probe data streams in.
Grace Parallel Hash Join
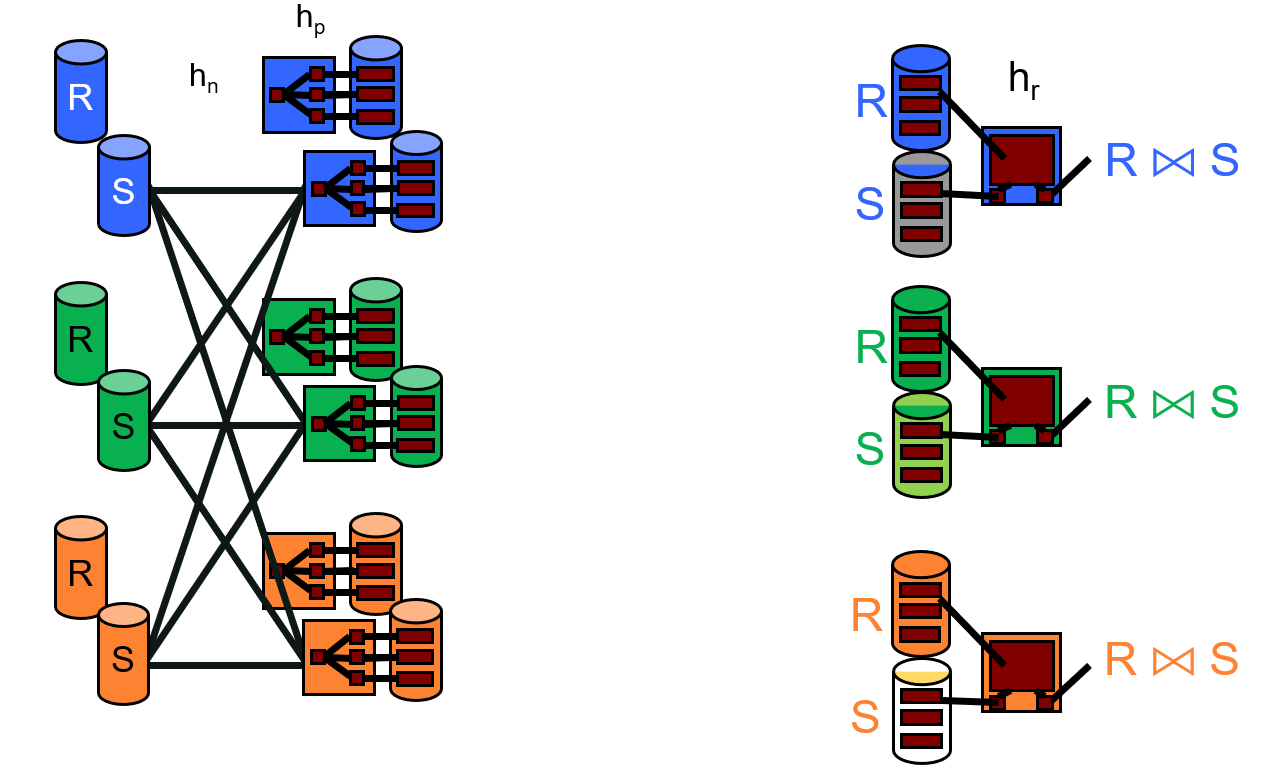
- Pass 1: parallel streaming
- Pass 2: local Grace Hash Join per node
- Every node waits for Pass 1 to end, and works at its top speed in Pass 2.
Sorting
- Pass 0: shuffle data across machines
- Pass 1-n: independently run as single-node sorting
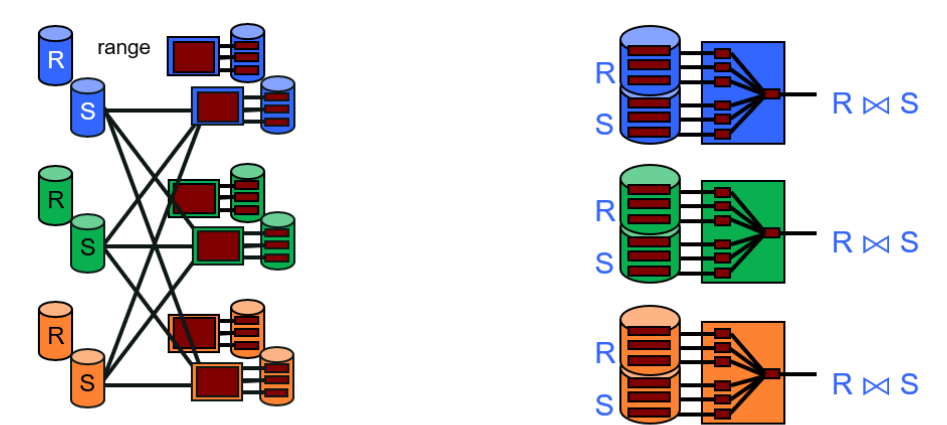
Sort-Merge Join
- Pass 0 to n-1: like parallel sorting above, but do it twice: once for each relation with same ranges
- Pass n: merge join partitions locally on each node
Note: this picture is a 2-pass sort
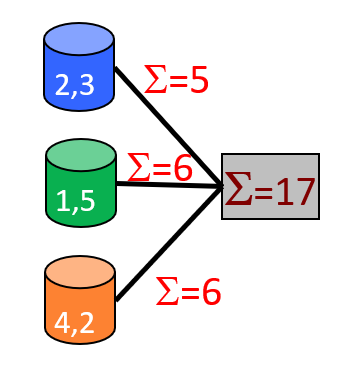
Parallel Aggregates
Hierarchical aggregation